The Correct Format for Documenting Risks?
Working with risks is a task various departments and roles have to perform throughout a large company or cooperations. Every single one of these as a different, valid, and important perspective on the same thing and thus has different requirements and wishes. This can easily result in overly complex situations and a lot of conflicts. Here a little insight into potential issues and risks when working with risks.
Upper management, CEOs, boards
All three mentioned in this chapter’s title are obliged to create rainy-day-funds, thus create reserves for the case something that was calculated as being a risk actually happens. While everybody hopes that bad things never happen, accepting a risk does have practical implications. The upper level in a company needs to know both the potential impact and the probability or incidence of a certain negative event. While a tuple of a fraction and value in the local currency might be a desired and the requested format, the real world is a little bit more complicated. Using a 20-sided dice as a reference, the probability of rolling a 1, or to encounter the worst-case scenario, might obviously be 1/20, but if your aim is to roll a 16 or higher, rolling a 15 still is a failure. Thus, you have a 4/20 chance of succeeding and a 16/20 of failing. Treating a 1 as the worse-case scenario, you have a 15/20 chance of failing, but not hitting the worst-case scenario. Imagining that rolling the numbers 15-2 implies various different implications, you result in a function showing different implications with different probabilities. In the real world, obviously, the considered scenarios are rarely as simple as simple as rolling a single D20. But, talking upper management, this is the complexity or abstraction level, the team preparing the numbers and reports will aim at.
It should be easy to understand, that from this this perspective practical issues and vulnerabilities and practical damages are usually irrelevant. With the potential exception of human life, it’s solely about money and dry, manageable numbers.
Talking to people working at this level can often be very irritating, as they sincerely do not care about reasons and practical implications, for them a risk exists, or it doesn’t. When being in a discussion with them, or the all the other groups described in this post, it is vital to talk about individual scopes and understand where one comes from and what they have to deliver at the end of the day.
Operations and tech-people
Operations and tech-people are driven by keeping their systems running stably. Being regularly confronted with vulnerability reports, their used to patching multiple systems in a short period of time. Following a hard schedule, they often have to work out, whether an emergency patch “right now” is necessary, or they can/may wait until the next maintenance window. Prioritization and decision making at this level is often based on the CVSS score (https://www.first.org/cvss/) assigned to a specific vulnerability. While CVSS offers numbered scores, they are usually referred to by a simple naming scheme reaching from a “low” to a “critical” criticality. Coming from here, issues rated as high or critical usually have to be addressed within hours, low issues, well, highly depend on the amount of daily work. Looking at CVSS and challenges in operations, many discussions refer to Confidentiality, Availability, and Integrity (CIA) impacts and can very often be a binary statement in combination with a rough estimation of a likelihood / probability of something going wrong (low to high, or small to large).
The people in ops rarely work with specific probability values / numbers or state an impact as a monetary value. For their scope this simply isn’t necessary.
CISOs and security management
CISOs tend to be challenged with situations in which they have too many tasks and too little resources. I.e., a spontaneous patch day, during which the many systems have to be patched in a very short amount of time. As such prioritization is a typical and critical task, a risk-based approach can be used to combine the criticality of systems and their exposure, even over multiple vulnerabilities if necessary.
Coming from here his perspective is often on system level with the aim of telling his team’s and the operations teams, which system has to be patched at which point of time. The same approach applies, when purchasing new security solutions/tools. Based on the combination of likelihood of an issue and the current state/quality of the already applied measures he prioritizes which systems are more or less important when defining a scope of a project.
Depending on their individual history and the history of the surrounding company, the CISO and security management group/level/environment can either be more management and live styles which can typically be found in upper management or be more technical and follow the Ops world. While always being a mix of both worlds, one can usually see a strong tendency into one of both worlds.
Practically it’s a hybrid addressing Ops’ issues and reporting to upper management and as such has to translate between “low” and “500€ per year. Due to a typical lack of official tables and the lack of an instance who is in charge of creating these tables, this often results in big conflicts. They an neither force Ops to work with actual numbers nor convince upper management to work with words and phrases.
Thinking tree structures and inheritance
All three scopes can easily be visualized in the following simple tree-diagram.
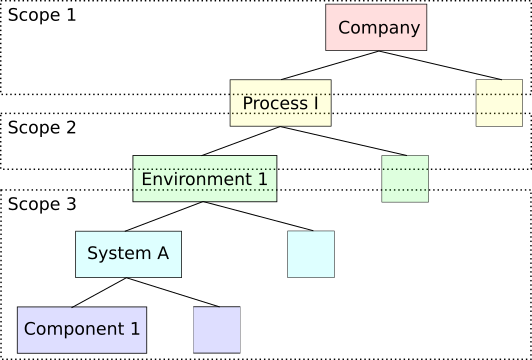
Following the lines, a critical vulnerability in a specific component can result in the downtime of system, which in return brings a whole environment into a stall, thus risking the fulfilment of a process and resulting in implications for the overall company. While, as described before the details of the vulnerability are irrelevant for Scope 1, the influence of it’s impact can trigger a documented risk scenario within their scope.
The other way round, the overall company might identify a process as highly critical, as the company simply relies on it. This results in certain requirements, i.e. a very high availability rate. This in return results in a very high availability rate for the underlying environment, which inherits the rate to the underlying system which again results in requiring redundancy for underlying components and forces Ops to even install certain patches with a low criticality in the same timeframe as critical ones.
While the described paths may seem trivial from the outside, when being stuck within any one of the three scopes and fighting tight schedules and management/shareholder pressure things are very different. All three groups of people may work at very different speeds, following incompatible priorities. This can easily create unnecessary pressure and conflict, especially when trying to identify a single party which has to establish the interface between both scopes.
Strategy
Understanding that there are three different worlds working with the same data on different levels and in different colours, it should be easy to work out a general strategy and maybe toolset to establish a working structure. Obviously, the already mentioned different working speeds and priorities can be very tough. On average, all three groups have to deliver or work with their first dataset at the same point in time. So following the picture above, the data from Scope 3 will not have been accumulated into the data of Scope 2 in time to be passed on as numbers to Scope 3. The overall strategy has to intially provide options to create estimations and then over time confirm or correct the estimations with real data.
Practically all three groups have to work with more or less rough approximations at some point in time. Here it’s just important to note and understand the applicable data quality and rate the quality of the overall result. Over time the numbers in Scope 3 should reach a very very high accuracy, as they’re inheritted from the components up to the processes.
Life will be much easier for all involved parties, when each of their individual requirements have been documented and used as a basis for translation tables between the differen scopes.
Words, phrases and misunderstandings
“Your approach doesn’t solve the problem” should very often be a “>Your< approach doesn’t solve >my< problem” and, well, is fully valid. Every group in the overall company has their own perspective, which is sufficient for their scope and their issues. Conflicts emerge, as people tend to forget the opposite’s scope when discussing deliverables and reports.
This being said, don’t do so! “Their” approach isn’t wrong, they’re just solving a different problem. :)